
انواع الگوریتم های یادگیری ماشین را با موارد استفاده نهایی آن ها یاد بگیرید

در این مقاله، انواع مختلفی از الگوریتم های یادگیری ماشین و موارد استفاده آن ها را بررسی خواهیم کرد. ما بررسی خواهیم کرد که چگونه Baidu از تشخیص چهره مبتنی بر یادگیری ماشین نظارت شده برای بازرسی هوشمند فرودگاه استفاده می کند و Google چطور از یادگیری تقویتی برای ایجاد یک پلتفرم هوشمند استفاده می
در این مقاله، انواع مختلفی از الگوریتم های یادگیری ماشین و موارد استفاده آن ها را بررسی خواهیم کرد. ما بررسی خواهیم کرد که چگونه Baidu از تشخیص چهره مبتنی بر یادگیری ماشین نظارت شده برای بازرسی هوشمند فرودگاه استفاده می کند و Google چطور از یادگیری تقویتی برای ایجاد یک پلتفرم هوشمند استفاده می کند تا به سوالات شما پاسخ می دهد.
یادگیری ماشین یک حوزه گسترده است، اما به سه کلاس یادگیری نظارت شده، بدون نظارت و یادگیری تقویتی دسته بندی می شود. این سه الگو در همه جا برای توانمندسازی برنامه های هوشمند مورد استفاده قرار می گیرند. ما به موارد مهم استفاده این الگو ها خواهیم پرداخت و این که آن ها چگونه دنیای امروز ما را متحول کرده اند.
یادگیری ماشین چیست؟
یادگیری ماشین به سیستم ها اجازه می دهد تا بطور خودگردان، بدون هیچ پشتیبانی خارجی، تصمیم گیری کنند. این تصمیمات در شرایطی اتخاذ می شود که دستگاه قادر به یادگیری از داده باشد و الگوهای اساسی موجود در آن را درک کند. سپس، از طریق تطبیق الگو و تحلیل بیشتر، نتیجه را که می تواند یک کلاسه بندی یا یک پیش بینی باشد، برمی گردانند.
صبر کنید! آیا کاربرد های یادگیری ماشین در زندگی واقعی را بررسی کرده اید؟
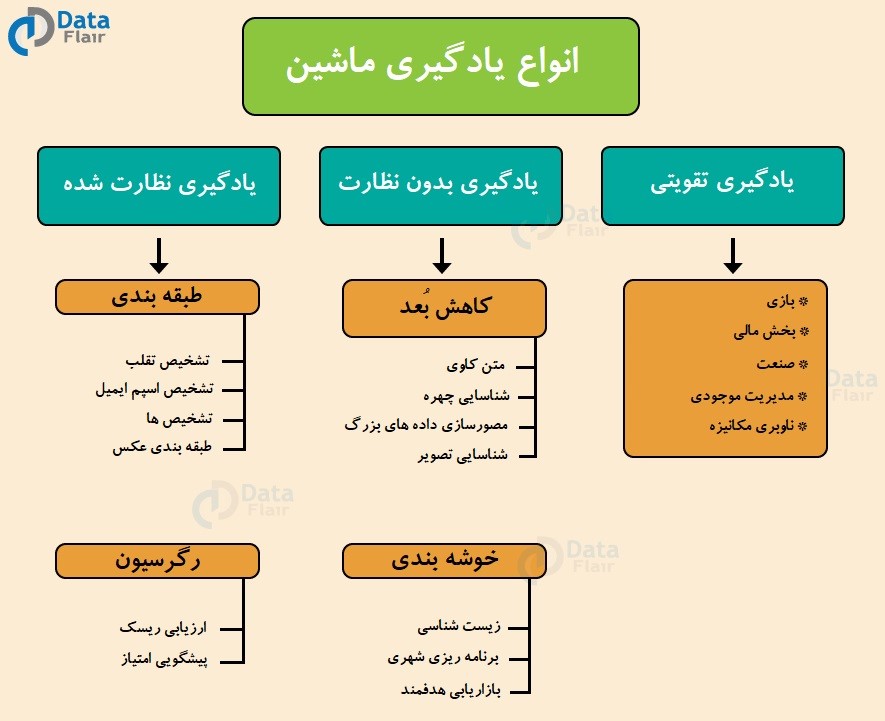
انواع یادگیری ماشین
سه نوع الگوریتم مهم یادگیری ماشین وجود دارد که در این آموزش به آن ها خواهیم پرداخت :
- یادگیری نظارت شده
- یادگیری بدون نظارت
- یادگیری تقویتی
یادگیری نظارت شده
یادگیری نظارت شده محبوب ترین الگو برای انجام عملیات یادگیری ماشین است. به طور گسترده برای داده هایی استفاده می شود که نگاشت دقیقی بین داده های ورودی – خروجی وجود دارد. در این حالت، مجموعه داده ها، برچسب زده شده اند، به این معنی که الگوریتم، ویژگی ها را به طور واضح مشخص کرده و براساس آن، پیش بینی ها یا کلاسه بندی را انجام می دهد. با انجام مرحله آموزش، الگوریتم قادر به شناسایی روابط بین دو متغیر است به گونه ای که می توان نتیجه جدیدی را پیش بینی کرد.
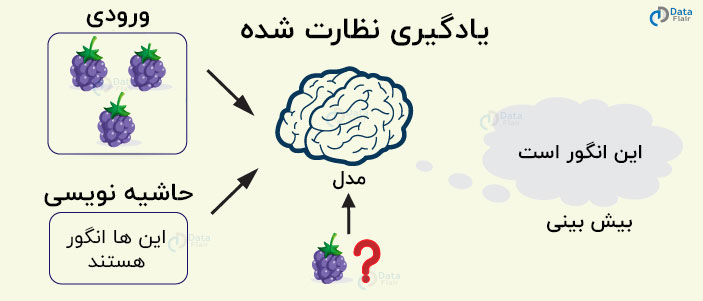
الگوریتم های یادگیری نظارت شده ی حاصل، وظیفه محور هستند. به همان اندازه که نمونه های بیشتری فراهم می کنیم، الگوریتم قادر به یادگیری صحیح تر است تا بتواند وظیفه اش را انجام داده و خروجی دقیق تری به ما بدهد. برخی از الگوریتم هایی که تحت یادگیری نظارت شده قرار می گیرند عبارتند از:
رگرسیون خطی
در رگرسیون خطی، رابطه خطی بین دو یا چند متغیر را اندازه گیری می کنیم. براساس این رابطه، پیش بینی هایی را انجام می دهیم که از این الگوی خطی پیروی می کنند.
جنگل تصادفی
جنگل های تصادفی یک روش یادگیری گروهی هستند که برای کلاسه بندی، رگرسیون و همچنین سایر کار ها از طریق ساخت درختان تصمیم گیری و تهیه خروجی به عنوان یک کلاس که مُد یا میانگین درختان منحصربفرد اصلی است، انجام می گیرند.
تقویت گرادیان
تقویت گرادیان، یک روش یادگیری گروهی است که مجموعه ای از چندین درخت تصمیم گیری ضعیف است که به یک کلاسه بند قدرتمند منتهی می شود.
ماشین بردار پشتیبان
SVM ها کلاسه بند های قدرتمندی هستند که با کمک ابرصفحه ها، برای طبقه بندی مجموعه داده های دودویی (باینری) به دو کلاس، استفاده می شوند.
رگرسیون لجستیک
این روش با استفاده از منحنی S زنگوله ای شکل ایجاد می شود که با کمک تابع logit برای دسته بندی داده ها در کلاس مربوطه شان تولید می شود.
شبکه های عصبی مصنوعی
شبکه های عصبی مصنوعی به تقلید از مغز انسان مدلسازی می شوند و در طول زمان از داده ها یاد می گیرند. آن ها بخش وسیع تری از یادگیری ماشین را تشکیل می دهند که یادگیری عمیق نامیده می شود.
موارد کاربرد یادگیری نظارت شده
تشخیص چهره یکی از محبوب ترین کاربردهای یادگیری نظارت شده و مخصوصا شبکه های عصبی مصنوعی است. شبکه عصبی کانولوشنی ( CNN ) نوعی شبکه های عصبی مصنوعی است که برای شناسایی چهره افراد مورد استفاده قرار می گیرد. این مدل ها می توانند از طریق فیلتر های مختلف ویژگی هایی از تصویر ترسیم کنند. در نهایت، اگر بین تصویر ورودی و تصویر موجود در پایگاه داده، نمره شباهت بالایی وجود داشت، یک مشابه قطعی ارائه می شود.
Baidu ، برترین شرکت موتور جستجوی چین، در زمینه تشخیص چهره سرمایه گذاری کرده است. در حالی که پیش از این، سیستم های تشخیص چهره را در تشکیلات امنیتی خود نصب کرده بود، اکنون این فناوری را در فرودگاه های اصلی چین توسعه می دهد. Baidu فناوری تشخیص چهره را در اختیار فرودگاه ها قرار می دهد تا امکان دسترسی به کارکنان هواپیما و پرسنل را فراهم می کند. بنابراین، مسافران وقتی می توانند به راحتی با اسکن چهره شان سوار پرواز شوند، دیگر مجبور نیستند برای بازرسی پرواز، در صف های طولانی منتظر بمانند.
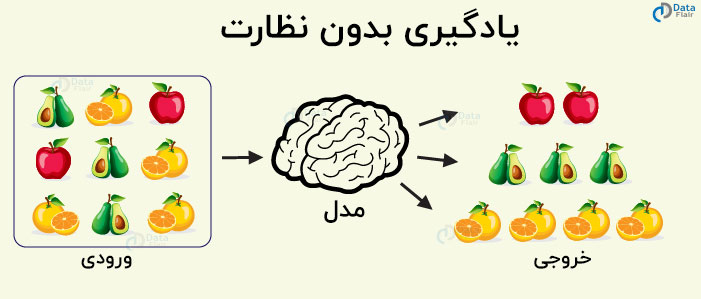
یادگیری بدون نظارت
در مورد الگوریتم یادگیری بدون نظارت، داده ها صریحا در کلاس های مختلف برچسب گذاری نمی شوند، یعنی هیچ برچسبی وجود ندارد. این مدل با یافتن الگوهای ضمنی قادر به یادگیری داده است. الگوریتم های یادگیری بدون نظارت، داده ها را براساس تراکم، ساختار، بخش های مشابه و دیگر ویژگی های مشابه، شناسایی می کنند. الگوریتم های یادگیری بدون نظارت مبتنی بر یادگیری Hebbian هستند. تحلیل خوشه یکی از تکنیک های بسیار پرکاربرد در یادگیری نظارت شده می باشد. بیایید نگاهی به برخی از الگوریتم های مهم بیندازیم که تحت یادگیری بدون نظارت قرار دارند.
خوشه بندی
خوشه بندی، که به عنوان آنالیز خوشه ای نیز شناخته می شود، تکنیکی برای گروه بندی مجموعه اشیا مشابه در همان گروه می باشد که متفاوت از اشیا گروه دیگر است. برخی از روش های مهم خوشه بندی به شرح زیر هستند:
۱- K-meams
هدف الگوریتم خوشه بندی k-means، تقسیم n مشاهده در داده ها به k خوشه است به گونه ای که هر مشاهده متعلق به خوشه ای با نزدیکترین میانگین است. این به عنوان نمونه اولیه خوشه عمل می کند.
۲- DBSCAN
این یک روش خوشه بندی است که داده ها را بر اساس تراکم، گروه بندی می کند. این روش نقاطی که در فضا داده می شوند را گروه بندی کرده و نقاط خارج از منطقه کم تراکم را علامت گذاری می کند.
۳- خوشه بندی سلسله مراتبی
در این نوع خوشه بندی، سلسله مراتبی از خوشه ها ساخته می شود.
تشخیص ناهنجاری
تکنیک های تشخیص ناهنجاری، با استفاده از این فرض که اکثر نمونه های داده با مشاهده مواردی که متناسب با بقیه مجموعه داده هستند، نرمال می باشد، داده های پرت را داده های بدون برچسب تشخیص می دهند.
خودرمزگذار ها ( Autoencoders )
خودرمزگذار ها نوعی از شبکه های عصبی هستند که در یادگیری بدون نظارت برای یادگیری بازنمایی مورد استفاده قرار می گیرند. آن ها در حذف نویز و کاهش ابعاد به کار می روند.
شبکه باور عمیق
شبکه باور عمیق یک مدل گرافیکی مولد و همچنین یک کلاس از شبکه عصبی است که برای یادگیری بدون نظارت طراحی شده است. این مدل، به این جهت با شبکه های عصبی نظارت شده، متفاوت است که ورودی های خود را به طور احتمالی بازسازی می کند تا به عنوان تشخیص دهنده ویژگی عمل کند.
تحلیل مولفه های اصلی
تحلیل مولفه های اصلی یک کلاس از الگوی یادگیری بدون نظارت است که برای کاهش ابعاد داده مورد استفاده قرار می گیرد.
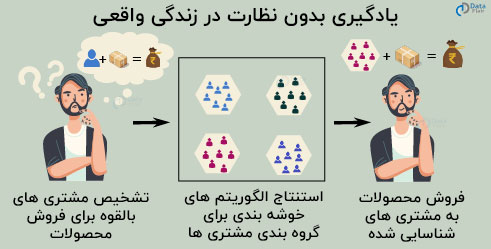
موارد استفاده یادگیری بدون نظارت
یکی از رایج ترین روش های یادگیری بدون نظارت، خوشه بندی است. با استفاده از خوشه بندی، مشاغل قادر به جذب مشتریان بالقوه برای فروش محصولات شان هستند. شرکت های فروش قادر به شناسایی مشتریانی هستند که به احتمال زیاد از خدمات آن ها استفاده می کنند. شرکت ها می توانند مشتریان را ارزیابی کرده و سپس تصمیم بگیرند محصول خود را بفروشند تا سود را به حداکثر برسانند.
یکی از این شرکت ها که با استفاده از یادگیری ماشین اقدام به تجزیه و تحلیل بازاریابی تجاری می کند، از استنتاج و پردازش داده های مشتری به منظور امکان دستیابی به آن ها برای بازاریابان استفاده می کند. آن ها با ارائه ی بینش های هوشمندانه به تیم بازاریابی، آن را یک گام جلوتر می برند و به آن ها اجازه می دهند تا حداکثر سود را از بازاریابی محصول خود به دست آورند.
یادگیری تقویتی
یادگیری تقویتی، حوزه های بیشتری از هوش مصنوعی را در بر می گیرد که به ماشین ها اجازه می دهد تا برای رسیدن به اهداف خود با محیط پویای اطراف خود در تعامل باشند. با این کار، ماشین ها و عامل های نرم افزاری می توانند رفتار ایده آل را در یک زمینه خاص ارزیابی کنند. با کمک این بازخورد پاداش، عامل ها قادر به یادگیری رفتار و بهبود آن در دراز مدت هستند. این پاداش بازخورد ساده به عنوان یک سیگنال تقویتی شناخته می شود.
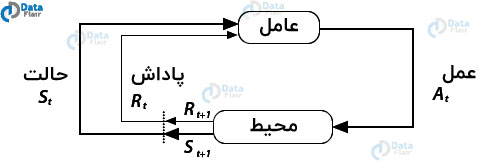
عامل در محیط، برای انجام اقداماتی که مبتنی بر وضعیت فعلی هستند، مورد نیاز است. این نوع یادگیری با یادگیری نظارت شده متفاوت است به این جهت که داده آموزشی دارای نگاشت خروجی است به طوری که مدل قادر به یادگیری پاسخ صحیح است. در حالی که، در مورد یادگیری تقویتی، هیچ کلید پاسخی وجود ندارد که هنگام انجام یک کار خاص، به عامل ارائه شود. وقتی که هیچ مجموعه داده آموزشی وجود ندارد، از تجربه خودش یاد می گیرد.
موارد استفاده یادگیری تقویتی
سیستم پرسش و پاسخ فعال (AQA) گوگل، از یادگیری تقویتی استفاده می کند. سیستمAQA گوگل، سؤالات پرسیده شده توسط کاربر را اصلاح می کند. به عنوان مثال، اگر از ربات AQA سؤال بپرسید – ” تاریخ تولد نیکولا تسلا چیست” ، آنگاه ربات آن را به سوالات مختلفی از جمله “سال تولد نیکولا تسلا چیست” ، ” تسلا کی به دنیا آمد؟” و ” چه زمانی روز تولد تسلا است؟ ” تنظیم می کند. این فرایند بازسازی از مدل قدیمی دنباله به دنباله ( sequence2sequence ) استفاده می کند، اما گوگل یادگیری تقویتی را در سیستم خود ادغام کرده است تا ارتباط بهتری با سیستم محیط مبتنی بر پرس و جو داشته باشد.
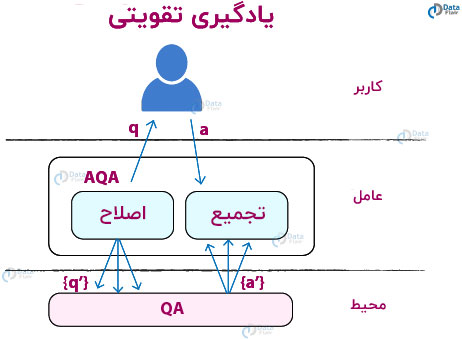
این یک انحراف از مدل سنتی دنباله به دنباله است به گونه ای که تمام کار ها با استفاده از روش های یادگیری تقویتی و روش های مبتنی بر گرادیان انجام می شود. یعنی برای یک سوال q0 داده شده، ما می خواهیم بهترین جواب ممکن a* را بدست آوریم. هدف بیشینه سازی a* = arg max a R (ajq0) است.
خلاصه
به عنوان نتیجه گیری از مقاله، ما به انواع مختلف الگو های یادگیری ماشین پرداختیم. ما یادگیری نظارت شده، بدون نظارت و تقویتی را مرور کردیم. ما همچنین چندین الگوریتم را که بخشی از این سه مقوله هستند، مورد بحث قرار دادیم. سپس، کاربرد های مختلف زندگی واقعی این الگوریتم ها مرور کردیم.
امیدواریم این مقاله را دوست داشته باشید اگر چیزی وجود دارد که می خواهید در مورد انواع الگوریتم یادگیری ماشین بدانید، در بخش نظرات بپرسید.
برچسب ها :
ناموجود- نظرات ارسال شده توسط شما، پس از تایید توسط مدیران سایت منتشر خواهد شد.
- نظراتی که حاوی تهمت یا افترا باشد منتشر نخواهد شد.
- نظراتی که به غیر از زبان فارسی یا غیر مرتبط با خبر باشد منتشر نخواهد شد.

ارسال نظر شما
مجموع نظرات : 0 در انتظار بررسی : 0 انتشار یافته : ۰